
Introdução
Quando se modela um banco de dados no Postgres, você provavelmente não presta muita atenção à ordem das colunas nas suas tabelas. Afinal, parece o tipo de coisa que não afetaria o armazenamento ou desempenho. Mas e se eu dissesse que simplesmente reordernar suas colunas poderia reduzir o tamanho das suas tabelas e índices em 20%? Isso não é um truque obscuro de banco de dados — é um resultado direto de como o Postgres alinha os dados no disco.
Neste post, vou explorar como funciona o alinhamento de colunas no Postgres, por que isso importa e como você pode otimizar suas tabelas para uma melhor eficiência. Com alguns exemplos práticos, você verá como até mesmo pequenas mudanças na ordem das colunas podem gerar melhorias mensuráveis.
Pesando uma tupla
Aqui, tupla é o mesmo que “linha” ou “registro”, ou seja, cada entrada de uma tabela. Equivalente a “row” em inglês.
Devido ao layout de tupla, o menor tamanho possível para uma tupla é 24 bytes.
|
|
Depois disso, para cada nova coluna que você adicionar na tupla, mais espaço será necessário:
|
|
Até aqui, tudo bem. Isso é exatamente o que você esperaria: quanto mais dados você tiver na sua tupla, mais espaço em disco ela utilizará. Além disso, nós esperamos que o uso em disco será diretamente relacionado aos tipos de dados presentes na tupla.
Em outras palavras, se você tem uma coluna integer, nós esperamos um tamanho de 24 + 4 = 28 bytes. Se nós temos uma coluna integer e uma smallint, nós esperamos um tamanho de 24 + 4 + 2 = 30 bytes.
Como podemos, então, explicar o seguinte resultado?
|
|
Como assim?! Nós acabamos de ver que uma tupla (integer, smallint) ocupa 30 bytes em disco, mas uma tupla (smallint, integer) ocupa 32 bytes! Isso acontece com outros tipos de dados, também:
|
|
Tuplas com formato (boolean, bigint) usam 21% mais espaço em disco que tuplas (bigint, boolean)!
O que está acontecendo aqui?
Alinhamento de dados
A resposta é alinhamento de dados (data alignment).
O Postgres vai adicionar “padding” (zeros) nos dados, de forma que eles estejam devidamente alinhados na camada física. Esse alinhamento garante um tempo de acesso mais rápido ao processar esses dados. [0]
Na realidade, isso se trata de um space-time tradeoff: nós estamos adicionando dados que são desnecessários, mas que garantirão um acesso mais rápido.
Representação visual
Vamos tentar visualizar como esses dados seriam armazenados em disco. Abaixo temos uma tupla (integer, smallint) devidamente alinhada:
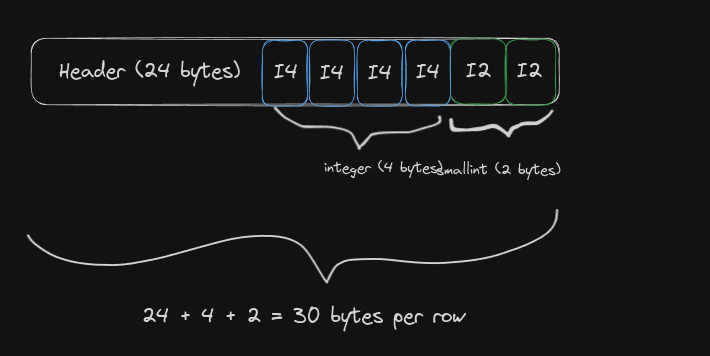
Contraste-a com a tupla desalinhada (smallint, integer):
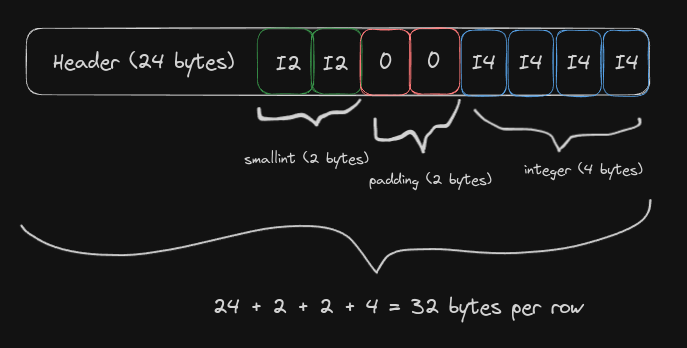
Perceba como o Postgres teve que adicionar zeros à coluna smallint para garantir o alinhamento necessário de 4 bytes.
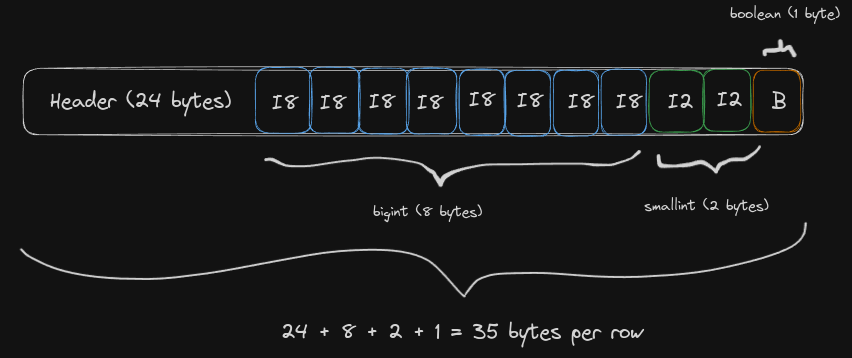
Abaixo temos outro exemplo, agora com (bigint, smallint, boolean) resultando numa tupla de 35 bytes.
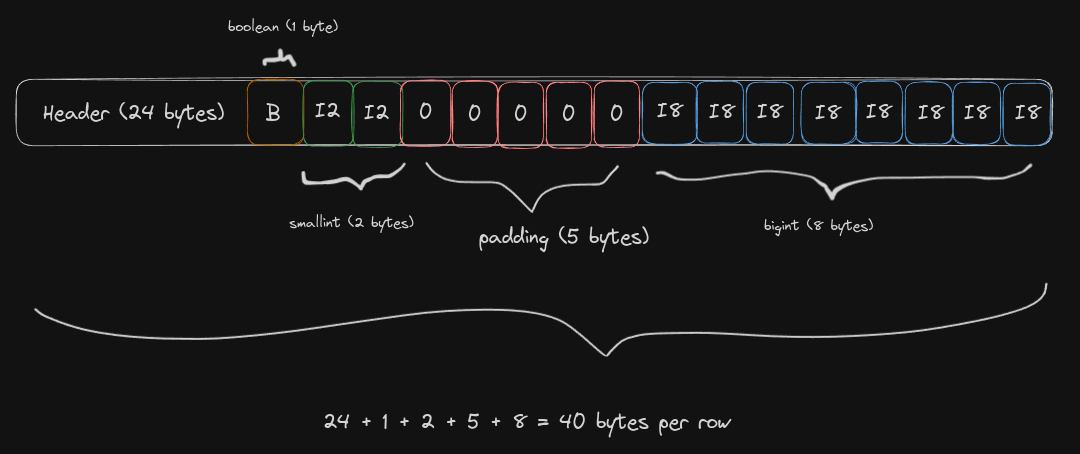
E a mesma tupla, numa ordem menos eficiente, resultando em 40 bytes por tupla
Calculando os limites de alinhamento
O que determina o alinhamento usado pelo Postgres? A partir da documentação:
typalign é o alinhamento necessário ao armazenar um valor desse tipo. Isso se aplica ao armazenamento em disco, bem como à maioria das representações do valor dentro do PostgreSQL. Quando vários valores são armazenados consecutivamente, como na representação de uma linha completa em disco, o padding é inserido antes de um dado desse tipo para que ele comece no limite especificado. O ponto de referência para o alinhamento é o início do primeiro dado na sequência. Os valores possíveis são:
- c = alinhamento char, ou seja, nenhum alinhamento necessário.
- s = alinhamento short (2 bytes na maioria das máquinas).
- i = alinhamento int (4 bytes na maioria das máquinas).
- d = alinhamento double (8 bytes em muitas máquinas, mas não em todas).
Podemos confirmar isso consultando diretamente a pg_type:
|
|
Você pode ver, por exemplo, que int8 requer um alinhamento de d (double, ou 8 bytes), enquanto int4 precisa de metade do espaço.
varchar e text funcionam de maneira diferente. Embora tenham um alinhamento de i, seu typlen é negativo. Por quê? Porque eles têm tamanho variável, ou seja, usam uma estrutura varlena.
O fato de esses dois campos terem comprimento variável não é realmente relevante para o alinhamento, exceto pelo fato de que tal coluna variável será alinhada em limites de 4 bytes (a menos que o valor esteja TOASTed, como veremos abaixo).
Também vale a pena mencionar que o tipo uuid é diferente. Ele tem um typlen de 16 bytes, mas possui alinhamento c (o que significa que não precisa de alinhamento prévio). Assim, você não precisa se preocupar se tiver uma coluna boolean logo antes de um uuid, por exemplo.
No código do Postgres, você encontrará esse valor sendo usado na macro MAXALIGN para determinar o alinhamento necessário.
|
|
NOTA: a documentação afirma que o padding é inserido antes […] desse tipo. Isso significa que, se tivermos uma tupla
(char, int4, char, int8), teremos 3 bytes de padding antes deint4e 7 bytes de padding antes deint8.
Alinhamento se aplica aos índices também!
O que muitas vezes é esquecido é que o alinhamento de dados não afeta apenas as tuplas das suas tabelas — ele também se aplica aos índices. Isso pode ser surpreendente porque geralmente pensamos nos índices como estruturas compactas e otimizadas que existem puramente para acelerar as consultas. No entanto, o Postgres garante que os dados nos índices sigam as mesmas regras de alinhamento que as linhas da tabela, o que significa que colunas desalinhadas podem inflar o tamanho dos seus índices da mesma forma que fazem com as tabelas.
Foi assim que eu descobri a importância do alinhamento de dados no Postgres. Eu tinha um índice (int8, int8), que reestruturei para (int4, int8) para resultar em um tamanho menor de tabela/índice. Imagine minha surpresa ao fazer o benchmark e perceber que o tamanho do índice não mudou!
Este é um ponto crítico a entender: colunas desalinhadas afetam seus índices também, potencialmente aumentando tanto o uso de disco quanto o consumo de memória. Manter os índices alinhados pode, portanto, ter um impacto significativo no desempenho e na eficiência dos recursos do banco de dados.
Como isso funciona na prática
|
|
Para uma única tabela, com apenas um dado desalinhado, a tabela devidamente alinhada usa 76 megabytes a menos (uma melhoria de 15%) e o índice devidamente alinhado usa 86 megabytes a menos (uma melhoria de 22%).
Essas tabelas experimentais têm 10 milhões de entradas, o que é um número pequeno para bancos de dados reais. Imagine o nível de melhoria que se pode encontrar nesses bancos de dados!
NOTA: É importante mencionar que os benefícios de uma tabela devidamente alinhada não são exclusivos do armazenamento. Isso provavelmente levará a ganhos de desempenho também.
É intuitivamente fácil entender por que isso acontece. Com um melhor alinhamento de dados, suas tuplas serão menores. Com tuplas menores, você encaixará mais tuplas por página. Com páginas mais compactas:
- Potencialmente, menos páginas precisarão ser recuperadas do disco.
- O Postgres pode encaixar mais tuplas na memória (ou seja, mais tuplas para o mesmo número de páginas em cache).
Não tenho tempo para medir o quanto o desempenho melhoraria, mas acredito que os ganhos de desempenho potenciais não seriam negligenciáveis.
Quando começar a se preocupar
Amigos não deixam amigos criarem tabelas desalinhadas. Mas você não quer necessariamente se tornar a polícia do alinhamento nas revisões de PR da sua empresa!

Startups, especialmente as de estágio inicial, muitas vezes têm um processo de desenvolvimento frenético, e economizar 10-20% de espaço em disco geralmente não é uma prioridade. Muitas vezes, essas economias são absolutamente irrelevantes nesse estágio. Então, quando sua equipe deve se preocupar com o alinhamento das tabelas?
A resposta certa depende muito do contexto por trás do seu produto, mas eventualmente você notará custos dramáticos relacionados a infraestrutura (especificamente aos seus bancos de dados), e talvez esse seja um bom ponto de partida.
No entanto, acredito que um engenheiro de software competente deve sempre ter esse fato em mente e, sempre que possível, fazer ajustes enquanto desenvolve funcionalidades. Não há necessidade de se preocupar demais com isso, mas tente manter suas tabelas alinhadas desde o início.
Isso economizará significativamente tempo no futuro. Refatorar seu modelo de dados não é fácil. Não se trata apenas de reorganizar as colunas da tabela, mas também de reorganizar seus índices (o que também significa reordenar seu padrão de consulta na camada de aplicação).
Na realidade, para startups em estágio inicial, minha recomendação é sempre ficar de olho em quão bem alinhados estão seus índices. Você pode reordenar as colunas da tabela mais tarde, mas preste muita atenção aos seus índices. Acho que essa é uma boa recomendação porque:
- Como mencionado acima, os índices são difíceis de reordenar. Você precisaria garantir que o padrão de acesso seja reordenado também, pois uma consulta em
(a, b)não usará um índice em(b, a). - É fácil mudar a ordem dos índices durante o desenvolvimento, já que eles são adicionados individualmente e não dependem de migrações anteriores.
- Mudar a ordem das colunas durante o desenvolvimento é difícil, pois elas geralmente são construídas com base em migrações anteriores.
- Refatorar o modelo de dados para reordenar as colunas da tabela, embora não seja trivial, não precisa de mudanças na camada de aplicação (a menos que você esteja fazendo algo incomum), então pode ser adiado para um estágio posterior.
Regra prática
Uma regra prática genérica que tenho usado nos últimos anos é, sempre que possível, definir colunas com base em uma ordem decrescente de tamanho dos tipos de dados.
Em outras palavras: comece com seus tipos de dados maiores (int8, float8, timestamp) e deixe os tipos de dados menores para o final. Isso naturalmente alinhará sua tabela.
Tenha em mente que essa regra é válida somente quando “todo o resto é igual”. Outros fatores, como cardinalidade ou até mesmo legibilidade, podem ter maior prioridade que alinhamento de dados, especialmente em se tratando de índices.
Uma nota sobre valores TOASTed
Alguns tipos de dados têm comprimento variável e seus valores podem ser armazenados em outro lugar se ficarem muito grande a ponto de uma tupla não caber em uma única página. Quando isso acontece, dizemos que o valor é TOASTed. Nesse cenário, a tupla conterá um ponteiro para os valores correspondentes.
Diferentes tipos de ponteiros podem existir dependendo do tamanho dos dados. Para ponteiros de um byte, nenhum alinhamento é necessário, enquanto um alinhamento de 4 bytes é aplicado a ponteiros de 4 bytes. Da documentação:
Valores com cabeçalhos de um byte não estão alinhados em nenhum limite particular, enquanto valores com cabeçalhos de quatro bytes estão alinhados em pelo menos um limite de quatro bytes; essa omissão de preenchimento de alinhamento proporciona economias de espaço adicionais que são significativas em comparação com valores curtos.
Isso se aplica a outros bancos de dados?
Precisamos considerar o alinhamento de dados ao trabalhar com bancos de dados além do Postgres? Aqui está o que descobri:
SQLite
Não. Aqui está uma citação do Richard Hipp (tradução minha; veja post para original):
O SQLite não preenche ou alinha colunas dentro de uma tupla. Tudo é compactado de forma justa, usando o mínimo de espaço. Duas consequências desse design:
- O SQLite tem que trabalhar mais (usar mais ciclos de CPU) para acessar dados dentro de uma tupla, uma vez que a tupla esteja na memória.
- O SQLite usa menos bytes em disco, menos memória e gasta menos tempo movendo conteúdo porque há menos bytes para mover.
Acreditamos que o benefício de #2 supera a desvantagem de #1, especialmente em hardware moderno, no qual #1 opera a partir do cache L1, enquanto #2 utiliza transferências de memória principal. Mas sua experiência pode variar dependendo do que você armazena no arquivo do banco de dados.
― drh
Para aqueles que estão familiarizados com a arquitetura do SQLite, diria que isso não é surpreendente e está alinhado com a filosofia do SQLite.
MySQL
O MySQL não é minha especialidade, então você vai querer se aprofundar mais para corroborar minhas descobertas. Estou apenas citando a documentação e adicionando alguns pensamentos meus, que não verifiquei. Você pode usar os links abaixo como ponto de partida para sua própria pesquisa.
NDB
Da documentação:
Tabelas NDB usam alinhamento de 4 bytes; todo armazenamento de dados NDB é feito em múltiplos de 4 bytes. Assim, um valor de coluna que normalmente ocuparia 15 bytes requer 16 bytes em uma tabela NDB. Por exemplo, em tabelas NDB, os tipos de coluna TINYINT, SMALLINT, MEDIUMINT e INTEGER (INT) requerem cada um 4 bytes de armazenamento por registro devido ao fator de alinhamento.
Com base no exposto, acredito que padding seria adicionado às colunas menores que 4 bytes.
InnoDB
Não consegui encontrar uma menção a alinhamento e preenchimento no capítulo 17 da documentação do MySQL, exceto talvez por este trecho:
[innodb_compression_failure_threshold_pct][define] a taxa de falha de compressão para uma tabela, como uma porcentagem, a partir da qual o MySQL começa a adicionar padding dentro das páginas comprimidas para evitar falhas de compressão caras.
Não é útil. Isso sugere padding no nível da página, mas queremos saber se as colunas são individualmente preenchidas. Bem, o MySQL é Oracle-open-source, então podemos olhar o código para tentar obter algumas dicas. Aqui está um trecho interessante de storage/innobase/row/row0mysql.cc:
|
|
Ok, claramente algo, em algum lugar, está preenchendo colunas no mecanismo de armazenamento InnoDB. No entanto, ao pesquisar na base de código do MySQL por usuários dessa função, tenho a impressão de que ela é usada apenas em alguns casos especiais (em vez de sempre verificar o alinhamento e preencher quando necessário, como o código do Postgres faz).
De qualquer forma, recomendo ao leitor que teste o snippet na seção “Como funciona na prática” no MySQL e analise os resultados. Algo me diz que tabelas desalinhadas não serão tão problemáticas no MySQL quanto são no Postgres.
Acompanhe a discussão no fórum Hacker News.
Notas
[0] Originalmente escrevi “ao ler páginas do disco” mas, conforme branko_d comentou no Hacker News, isso pode passar uma impressão errada: o ganho de performance ocorre ao processar dados corretamente alinhados (após eles terem sido lidos em disco), não ao ler páginas do disco. Essa é uma diferença sutil mas importante de se enfatizar. ^